The previous versions of vSphere supported deploying virtual machines from an OVF template with split VMDK files. However, starting 6.5 VMware removed support for chunked VMDK files. As a result, vSphere 6.5 may not deploy old templates. VMware fixed this issue by releasing a tool that combines VMDK files automatically. Multiple blogs covered this tool like in this post. In this blog post, the same procedure will be covered without VMware tool on Windows and Linux.
Get your Hand Dirty on Linux
1- Combine the chunks
Linux
The process on Linux is simple and it consists of two basic steps. First, combine all VMDK chunks into a single file. To do so, keep all chunks in a single folder and run the following command.
cat vmName-Disk1.vmdk.* > vmName-Disk1.vmdk
Windows
In windows, the step is slightly different. Instead of using cat command like in Linux, copy command with /b argument is used to combine files. Moreover, in the command add all chunks. For example, if disk 1 consists of three chunks. the command will be as following:
Finally save the file and you are done. Moreover, remember net to select the metadata checksum file (.mf) is exists as it is no more needed in Vsphere 6.5 and beyond.
A few days ago, I observed something is wrong in the workflow of a unit in a different department. Their workflow requires retrieving a video through FTP and then moving the files to another folder to be transcoded. The process of moving files from a folder to another is currently done manually. This method is not efficient nor proper.
Problem
There are some issues with their workflow. First, The unit has to perform the process manually, which is a distractive subtask for them. Moreover, the unit does not have any log for the process. Lastly, the files do not have specific arrival times.
The solution: Robocopy
Robocopy Syntax
A file replication solution solves The unit’s issue. There are many solutions that can be used, but for them I chose Robocopy.
According to Wikipedia, it a command line files and/or folder files replication developed by Microsoft. It is a replacement for Xcopy and it has additional options. Robocopy allows copying, moving files and folders inside Microsoft Environment. Also, it allows to create a list of files moved or copied and when.
Below, the Robocopy syntax used to fix this issue.
robocopy C:\Source C:\Destination *.*
The upper syntax will just copy all files in the source folder to the destination folder. However, the syntax does not keep a log of all copied files. Robocopy does provide a method to keep a log of all copied files. The below syntax shows how to do so.
/log lets the solution save the operation logs into a certain file. In this example, robocopy saves log file in logs.text appended. It is important to monitor and log every service because it allows system administrations know more about the service when it fails to work properly.
Hemo’s Take
There are many ways to solve this problem. However, I chose this approach because I find easy to understand and implement. Moreover, Robocopy can be used as a part of your backup Strategy.
Somewhere on earth in an IT department in a company there is a happy and excited junior system administrator at work. The junior is excited and happy because a brand-new server just arrived. Unfortunately, the happiness and excitement didn’t last long after knowing that the server came without OS as requested. What made things worse that our green junior was tasked to install CentOS onthis server with graphical interface.
In this tutorial, you will cover the process of installing CentOS, so the friend of our friend will not have a mini panic attack at work.
Pre-installation notes:
There are some things should be take into considerations before doing the installation process. First, make sure the hardware meets the minimum requirements of CentOS. Second, make sure the server is configured that it reads from the boot disc or PXE server. Lastly, you need a mouse and a keyboard to proceed in the installation.
Let’s install CentOS:
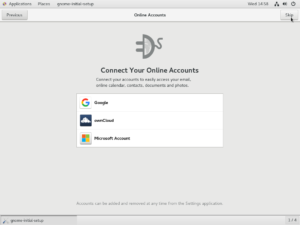
From main menu choose “Install CentOS 7” and wait for the next image
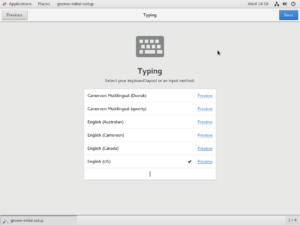
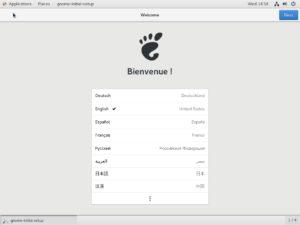
Select the language of the operating system. Remember, this is not the keyboard layout. Press Next to proceed.
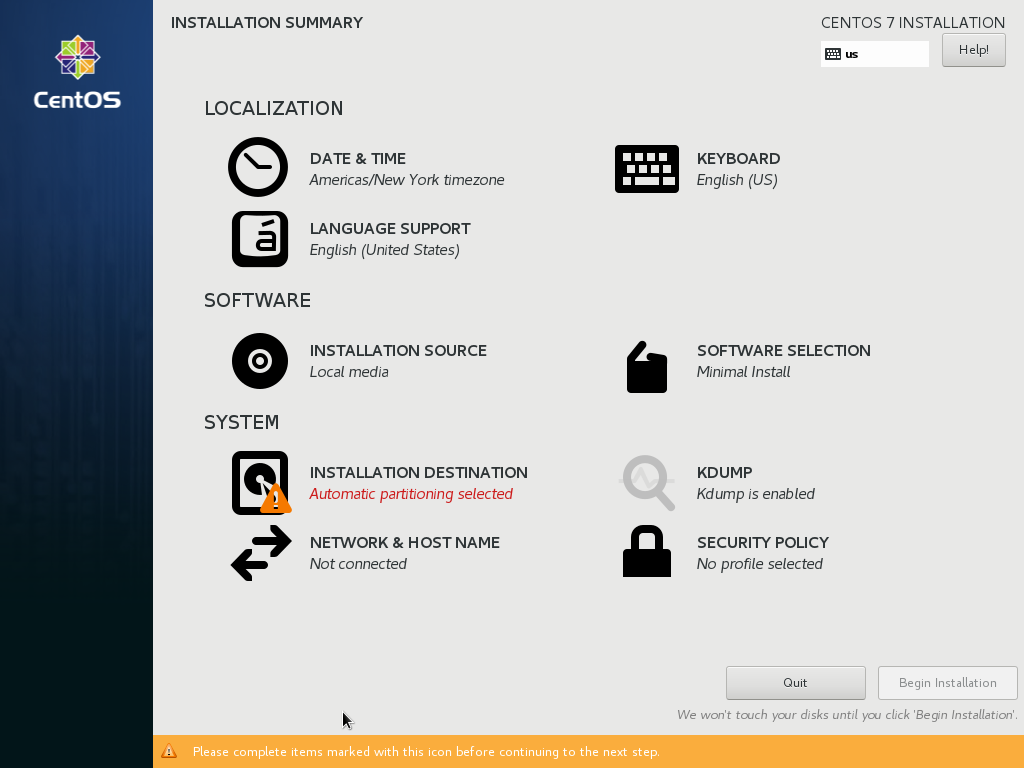
In this windows you will meet Installation Summary where you will configure Time and Date, Installation Destination, Network and Host Name and Software Selection. You will start with Date and Time, thus click on it.
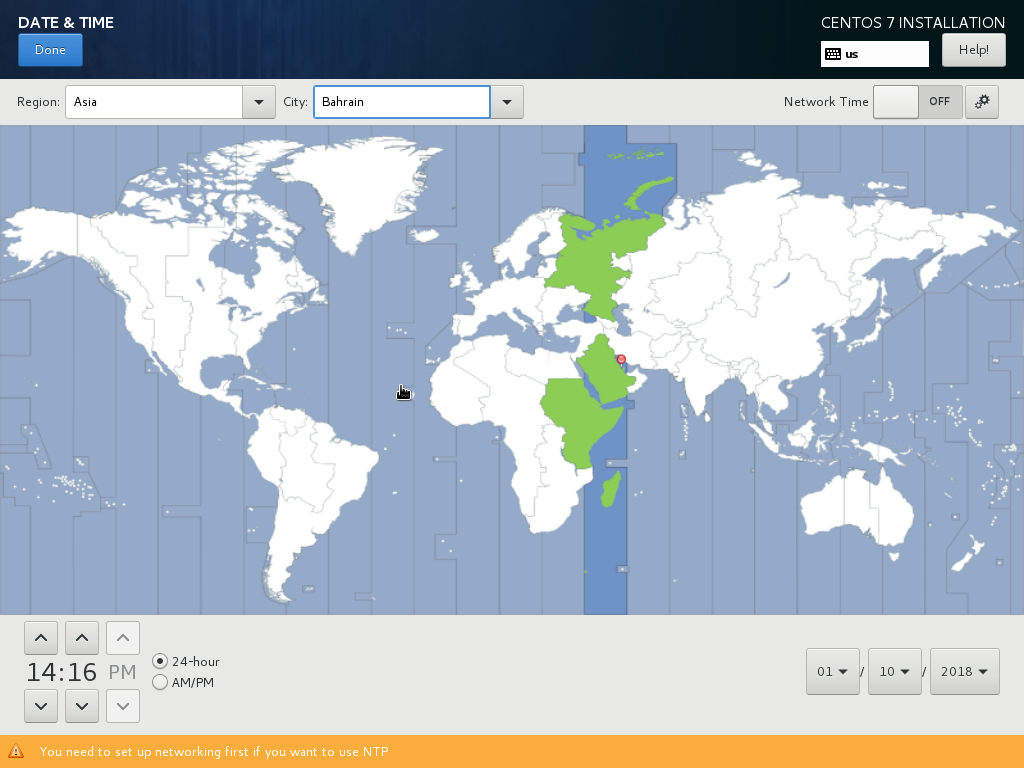
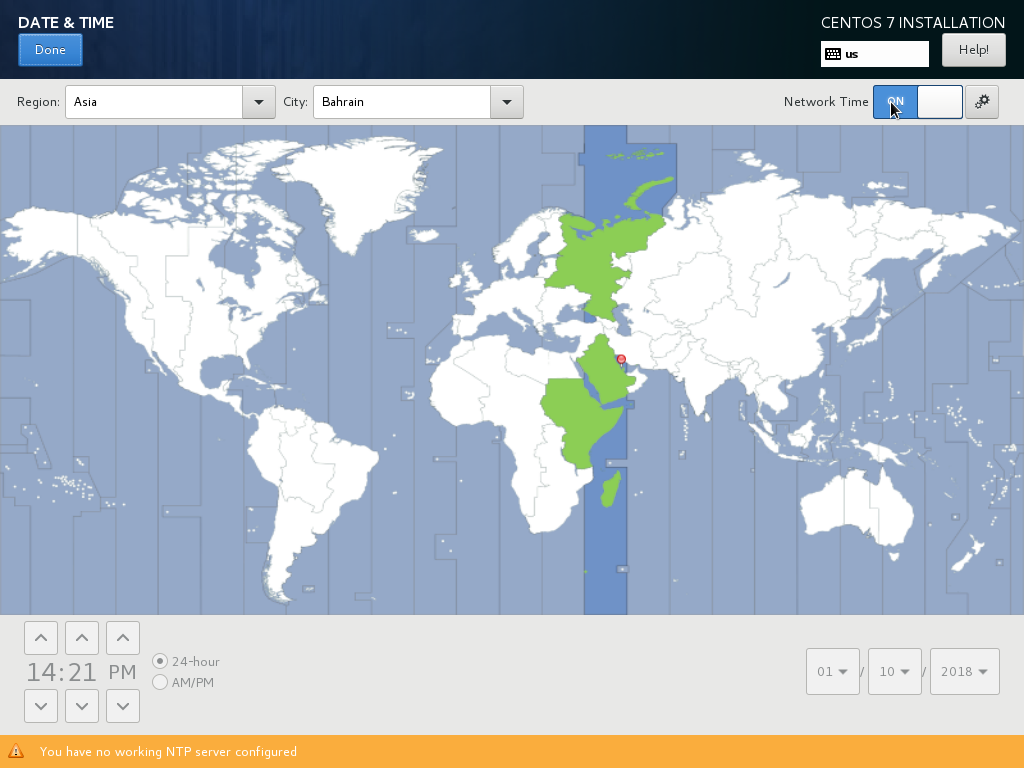
Next, select your city and timezone correctly. Do you not worry about network as you will fix it in a later stage. Press Done to go back to Installation Summary window.
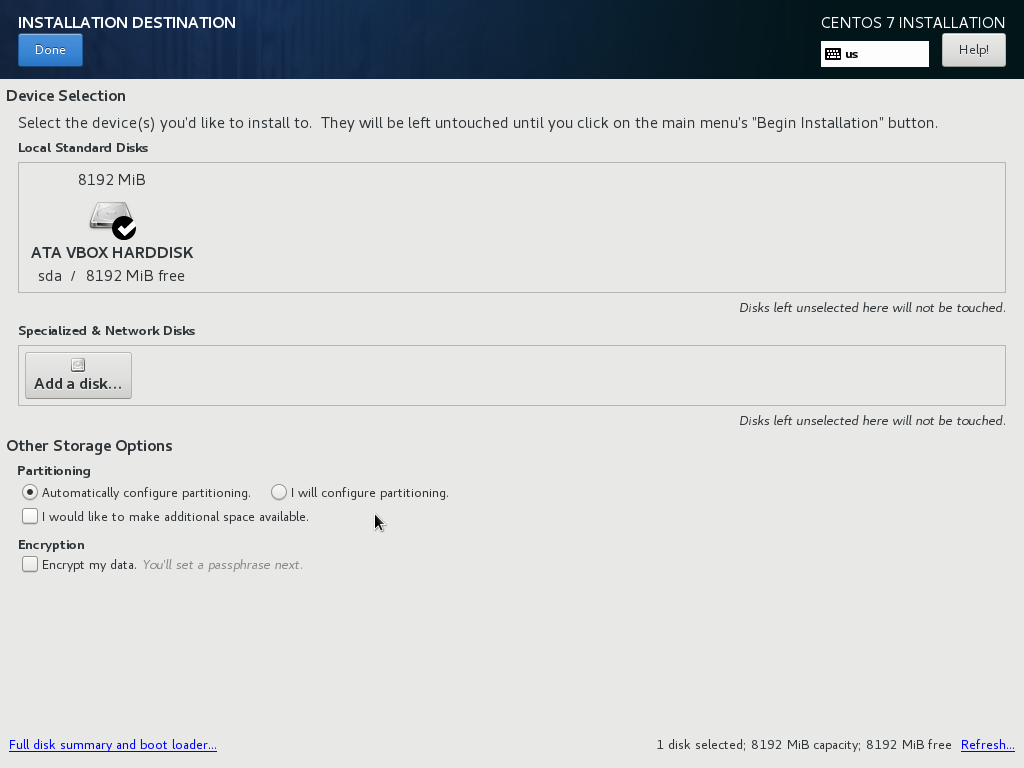
In Installation Summary window click Installation Destination.
Our senior told us that he needs a single partition in a single drive. As a result, there is nothing to be done here. So, press Done.
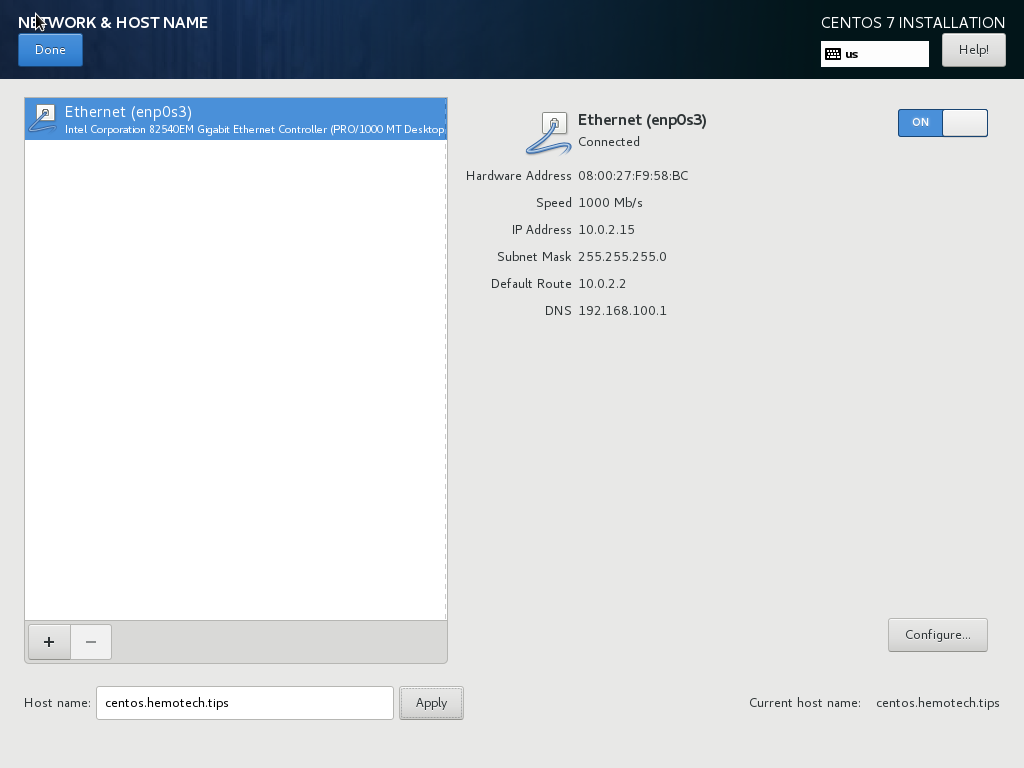
Next, configure Network and Host Name, so click on it.
In this window there are two main task to be done. First, you need to enable the network port by clicking On to turn it on and get an IP address from a DHCP server. Second, you need to give our server a proper host name. I named it “centos.hemotech.tips”. Finally, click on Done to go back to Installation Summary window.
Before proceeding to the next step, go back to Date and Time and enable Network Time and then click Done.
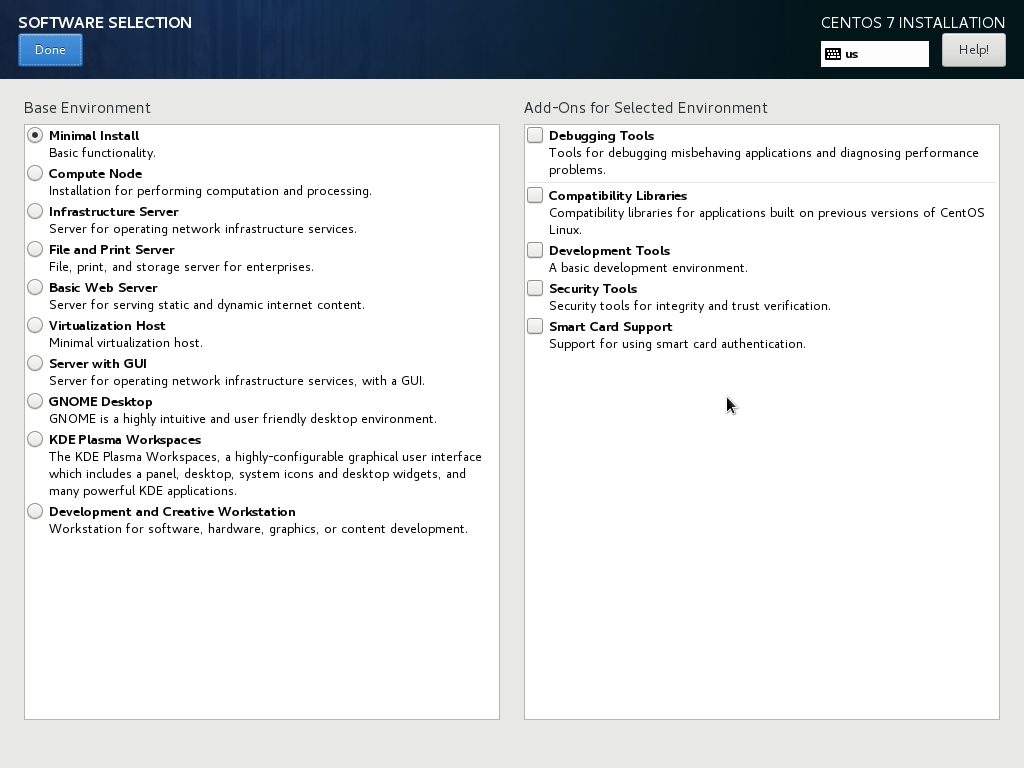
Lastly, configure the most critical step in the Installation Summary window. The step is Software Selection, so in the Installation Summary click on it.
By default, CentOS come in the Minimal Install option. Minimal Install option means that it will be installed without GUI and the minimal application. To install GNOME, click on GNOME Desktop and selection the same option as in the below image. Then click Done.
In the Installation Summary click Begin Installation.
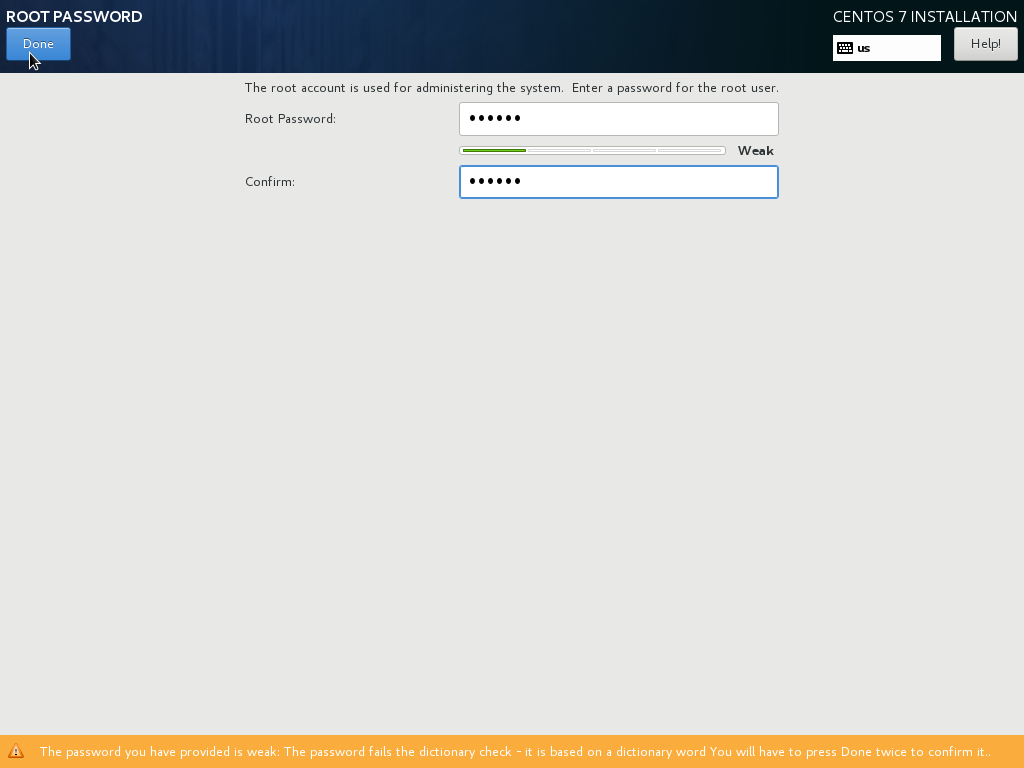
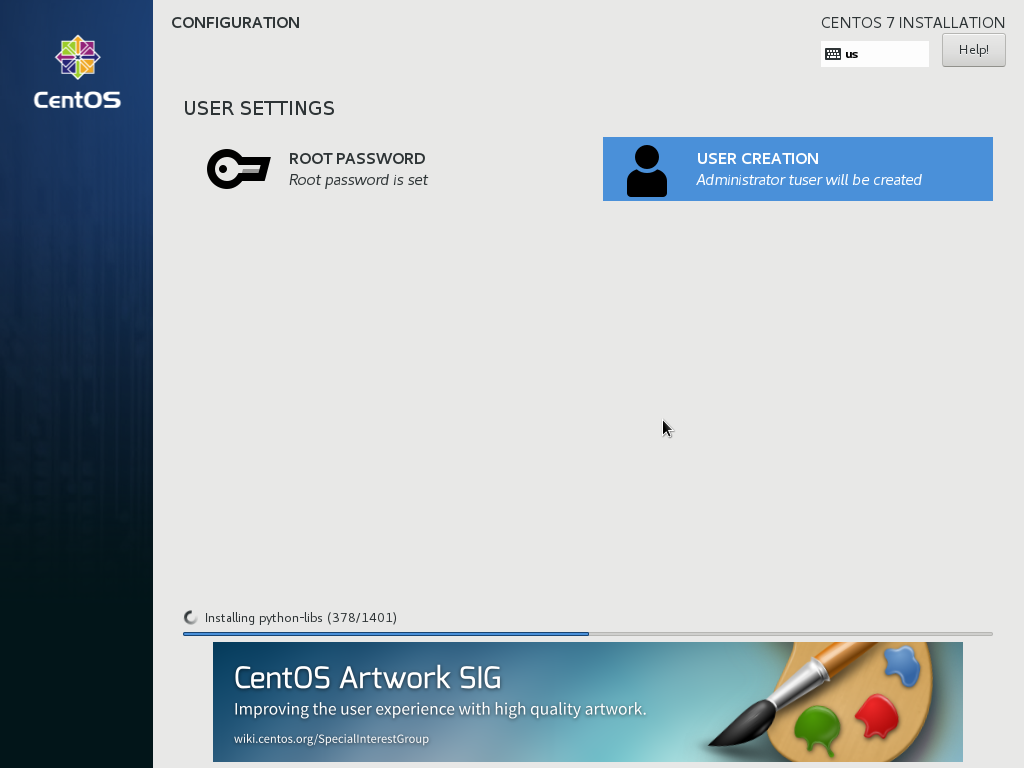
In this step, please insert the root access password. You shouldn’t add a weak password in a production server, but if you choose a weak password as I did, you need to press Done twice.
Next, you will create another administrative account. You should not use root account at any time.
Post Installation step. We are almost there 🙂
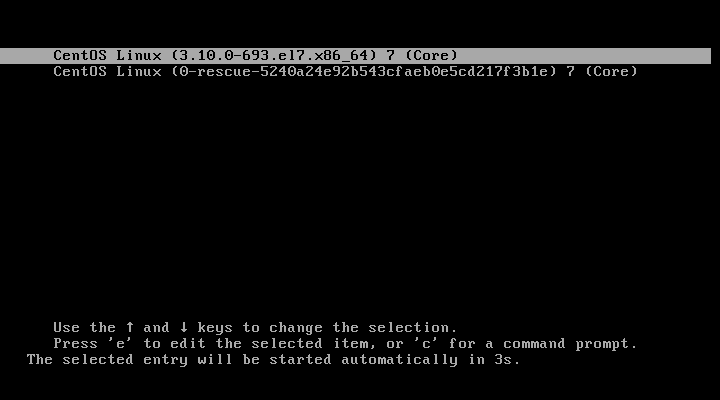
Reboot the system when prompted.
After the reboot the you will this list. Make sure you pick the one that does not have the work rescue.
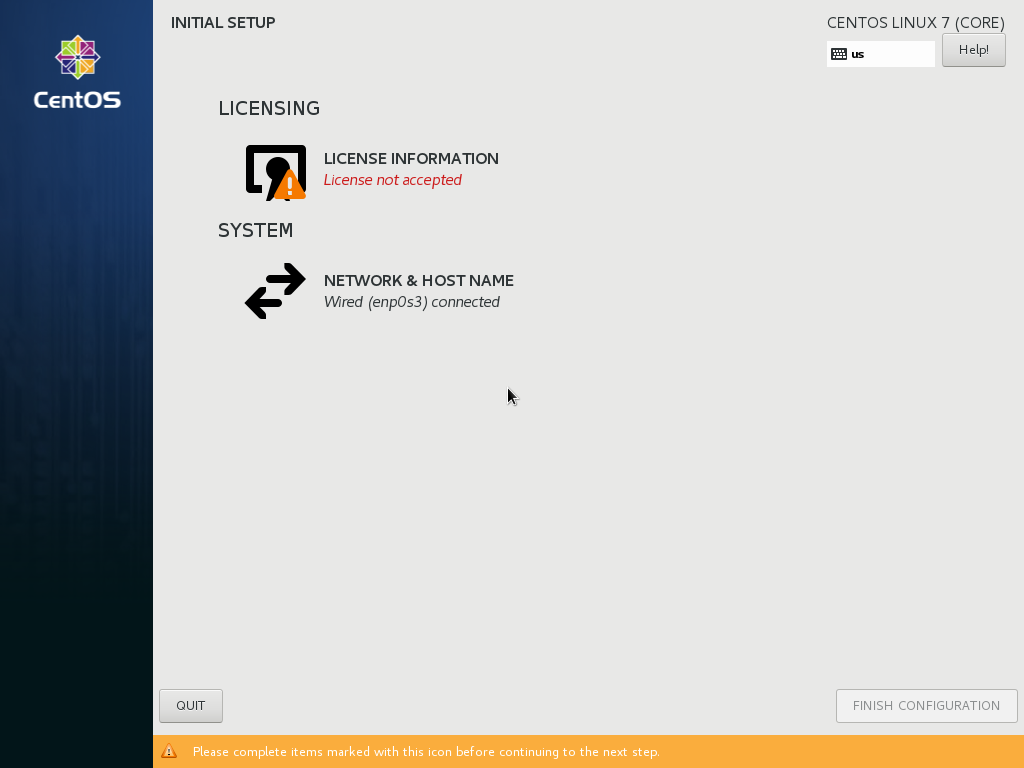
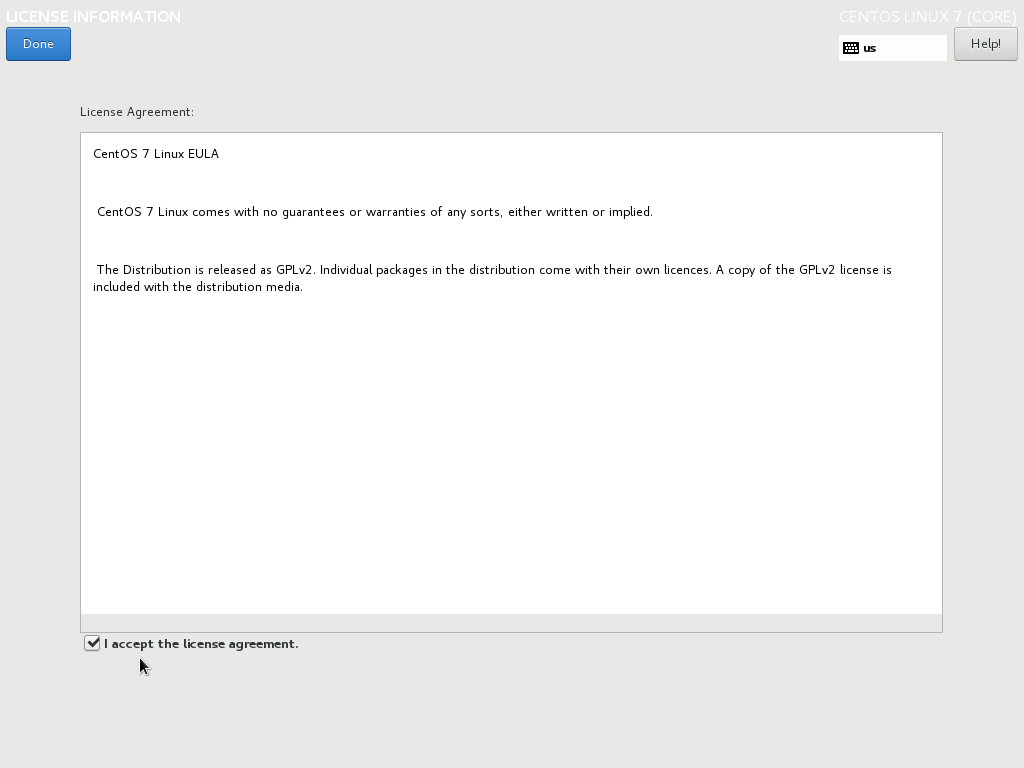
In the License Information window, check the check box and click Done.
Finally, click on Finish Installation.
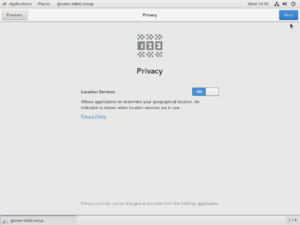
You do not need to change the settings here, so press Done or Skip.
You did it 🙂
Hemo’s Take:
Installing an operating requires a lot of steps, yet these steps are easy to understand and follow. Moreover, it critical for any system administrator to know how to install a Linux operating system.
As a tech worker, one of the skills that is a must is ability to use Linux. I won’t give you a walkthrough on how to write your first command or how to install it. However, I will talk about what do you need to know about Linux before using it. It is because Linux is not just an operating system. It is a philosophy and an interesting story in a form of an operating system.
What is Linux?
Linux is an open source operating system created by Linus Torvaldsfor x86 architecture and then for other architectures. Linux is greatly seen and used in data centres due to its performance, stability and flexibility.
Open Sauce ?!!
No not open sauce but open source. In software development world there are two different philosophies. The first believes no one should ever see how a certain application is made and nothing of its source code is open to public. This philosophy is called closed source or proprietary code. The other school believes that the source code must beopenfor public and they have the modify the code for their need, as long as they give credit to the original author.
Linux History
In 1991 when Linus Torvalds was still as student he found out that there isn’t a free and open sourced operating system that available for the public. So, he decided to build a new operating system that free and opensource.
Linux in depth… slightly
Over the years Linus is pretty much different than what it was in 1991. Also, due to availability of its code for the masses, there are many flavors of Linux. Each flavor is called a distribution. Each distribution differs from other by having different collection of application that are added to the system.
Distributions are split into two families; RedHat and Debian. Each family has its own characteristics. RedHat is a commercial Distribution that is free but you have to pay for it for its support. RedHat is also known for its stability and production ready. However, its update cycle is usually slower than the Debian family. Debian family is entirely free and tend to update every 6 months. Moreover, it is equipped with the latest technologies and applications.
Hemo’s Take
There isn’t the best distribution of Linux, because each distro has its benefits. As a result, you should choose the distro that matches your needs. Thus, I advise you to play with various distros until best fit is found and chosen.
One of the mistakes some novice IT pros do is suggesting using high-end consumer hardware instead of Server grade hardware. They suggest using high-end consumer grade hardware because it has better performance with the price range. However, price tag is just a factor in calculating overall cost of a certain asset. In this post, we will see why server-grade hardware is more beneficial than high-end consumer hardware.
Designed to last longer and more reliable!!
Server hardware is designed to have a longer time span that consumer hardware, because servers in general stay in production for a longer time than consumer hardware. Moreover, servers are designed to be on 24/7, unlike personal machines that most people turn them off for hours daily.
Mean time between failure or MTBF is a unit that measure the average time a component will take to failure under optimal operation conditions. As an example, according to western digital WD Gold MTBF is 2.5 million hours. On the other hand, consumer hard drives do not come with MTBF, however they tend to fail after 500 thousand hours.
Any enterprise will have more profit if they used their equipment for a longer time and less down time, because their ROI will be higher.
Fault tolerant
The other reason IT pro choose servers grade hardware over consumer grade hardware is its high fault tolerant and redundancy. As an example, servers come with two PSUs, to prevent downtime because of a dead PSU.
Fault tolerance allows devices to run even if one or more of its components is faulty. As a result, no service will be interrupted and sysadmins will be happy.
Support
Support provided to server grade hardware is often better than consumer grade hardware. Server grade hardware comes with better support packages, such as 24/7 support and on-site equipment replaced done by support representative. Moreover, vendor dedicate a certain specialist to large customers to ensure the representative is familiar with production environment and provide faster and better service.
Hemo’s Take
“It depends” is what is answer should be. As a system administrator, you should evaluate the value of each service and decide does it worth the support it comes with or not. Also think about the time and resource wasted from the down time.
Storage is one of the topics that is done differently in the corporate world than home environment. In SOHO data is usually stored in directly attached hard drives and in a device in a device over the network using a NAS. On the other side, corporate usually depend on something called a SAN to store their corporate data.
NAS?
Synology DS1511+ NAS – Courtesy of Synology
NAS stands for Network Attached Storage, which is basically generally a device over the network that is used to host and share information over the network. The device can serve multiple services or dedicated for file storage.
NAS is a file level storage. File level storage mean that the NAS and the client exchange files between them over the network, just like when a file download from a website. Moreover, with file level storage files are usually stored in a fixed location with a fixed storage capacity. As a result, expanding storage capacity is usually not possible and always require some downtime.
There are many protocols used for files storage such as SMB and AFP. Most NAS devices nowadays support and use SMB as its main file exchange protocol.
SAN?
emc VNXe1600 SAN – Courtesy of EMC
SAN stands for Storage Area Network and it is a network of multiple devices connected to serve a single purpose …storage. The network contains fiber matrix, storage controller and even pools of blazing fast hard drives.
Unlike NAS, SAN uses block level storage. In a nutshell, block level storage means that communication between the SAN and the client is treated like a directly attached hard drive into a motherboard. As a result, SAN mounts are visible as a local hard drive on clients.
There are two main protocols for SAN: iSCSI (Internet Small Computer Systems Interface) and FC (Fibre Channel). Most SAN nowadays use FC is built specifically for SAN and it is faster than iSCSI, but it is more expensive.
Why SAN over NAS?
Large enterprises use SAN over NAS for multiple reasons. First, SAN performance is higher than most NAS devices, due to the way storage area networks are built. Second, SAN allow easily to modify storage allocation of each storage mount. Also, the mount can reside on single hard drive, single virtual hard drive and event on two different building! Third, Storage are networks are real fault tolerant if built correctly. HP has proofed that a SAN can be bullet proof literally in an old TV commercial!!! The commercial can be viewed bellow.
Hemo’s Take
It is alright if you are not very familiar with SAN, as it is considered as big boys toys. Myself, I don’t have the permission to work with it yet, but one day both of us will work with it ?
Operating system installation is one of the most basic and simple process done by sysadmins or help-desk people, yet it is one of the most expensive processes for any business, because it wastes IT staff time and employees time. Besides being expensive and time consuming, it is also very repetitive and prone to errors.
The problem
Let’s image the following, your business decided to build an onsite training center at work with capacity of 25 trainees. The new center needs a new machine for each trainee in the center. Moreover, these machines come without an operating system, because you already have an enterprise license from Microsoft. Accomplishing this task will keep the entire team busy for the entire day! By the end of the day, you will have a dead tired team who spent an entire day on a single task, and training team who were idling due to uninstalled machines.
The traditional way the team is doing this task is by grabbing an installation disc and fill the prompted instruction, until the end. During this process, the staff member must be next to the machine to answer the required questions. The actual process can take up to an hour per machine.
The biggest problem with operating system installation is not the time it consumes, but the IT team might have 25 machines with 25 different configurations. Such difference in configuration may lead into future problems in the future.
Such process can be enhanced by complying two main principles. First, Automating the processes as much as possible. Second, unifying all the hardware and software as much as possible. Operating system installation automation complies these principles.
Automation?
In a nutshell, operating system installation is done using through running a PXE server, and creating a proper answer machine file which is used answer question asked during installation.
Available solutions
They are different solutions used for operating system automation. Microsoft suggests Microsoft Deployment Toolkit to automate their operating systems. Red Hat released Kickstart to automate its operating systems.
Hemo’s Take
Cloning is also a solution, but I suggest not to use it. The master image of the clones needs to be up to date to have all the chnages. Also, SA needs to run sysprep to change GUID and SID of each clone. Finally, cloning hides the history of the process. As a result, the SA does not know installation history.
In May 2017, a massive cyber-attack caused by WannaCry ransomware. Such attack has increased the awareness of the importance of backups. However, many system administrator, especially novice ones faced the consequences of improper backup strategies that are never tested. Such strategies mostly lead into a huge chunk of missing or useless data. Fortunately, there are a set of recommended tested strategies that insure no data loss as much as possible. One of these strategies is what is known as 3-2-1 Strategy Back up.
The number three means that each file must be three copies of each file. Moreover, it also means that all files are identical and have exact check sum value. Check summing is a calculation done using certain algorithms, that ensures integrity of data were not changed after sending them into a medium.
3-2-1 Backup
Three copies are recommended instead of three, because in some scenarios even the backup files might fail. An example of such scenarios is when a system is hit with a malware that encrypt all files attached. Different media is recommended because each medium has a different
Second, number 2 means these copies are save in at least two different back up media. These media could be a conventional hard disk drive, a tape, or even an optical disk such as DVD or Blu-ray. Moreover, cloud storage can be considered as a media, even though it uses one of the previously mentioned media.
Last, number 1 means that at least one copy must be offsite. It is advised that the offsite location is at least 25 KM away from the original copy. Offsite copies are critical when original location was affected by a catastrophic incident such as a flood, fire and earth quakes. Moreover, physical security should be implemented and assured when offsite location is run and manage by corporate itself.
Hemo’s Take
No matter how many copies do you have of a file if these copies are not identical and corrupted. Thus, after ensuring that files are copied as mentioned above, ensure that are the identical and retrievable every six months. You really do not want to get back to a backup and nothing is there.
Fault tolerance is one of the concepts that is put into consideration when designing an infrastructure. In a nutshell fault tolerance is the ability for a device or a system to operate, even when it is faulty. One of the technologies that is based on the concept is fault tolerance is RAID.
What is RAID?
RAID which stands for Redundant Array of Independent Drives is technology that allow multiple hard disk drives to work as a single entity. As a result, characteristics of these hard drives change based on its levels up used and it is mostly implemented in servers. There are multiple setups exists, but in this post, the main three RAID levels will be covered. The main three levels are level 0, level 1 and level 5.
RAID 0
Data distribution in RAID 0 (Courtesy of Wikimedia)
RAID level 0 or known as RAID zero or striping is a set up consists of two or more hard drives, where data is spit across all hard drives as seen in the picture above. Such setup allows data to be read and written times faster than the specs of each hard drive. However, in case of disk failure or data corruption in a hard drive, all data will be about useless.
RAID 1
Data Distribution in RAID 1 (Courtesy of Wikimedia)
RAID level 1 or known as mirroring or RAID 1 is a setup consists of two or more hard drives, where data is duplicated across all hard drives. As a result, data remain safe if a one hard drive is intact. On the other side, RAID 1 has its share of disadvantages. First, despite the amount of hard drives are added to the setup, only the capacity of the smallest hard drive will be used. Second, RAID 1 doesn’t provide any additional performance than standalone hard drive.
RAID 5
Data Distribution in RAID 5 ( Courtesy of Wikimedia)
RAID 5 that is also known as Striping with distributed sets is a setup consists of three or more hard drives. Unlike other levels, RAID 5 mechanism saves the piece of data on a hard drive and keep certain calculations on others and these calculations enable data to be recovered. Due to its mechanism RAID 5 provides continuous operation, even with a failed drive in the pool. Moreover, these calculations can lead toward a faster operation.
Hemo’s Take
RAID is a fun topic to discuss. IT pros can argue which RAID is the best RAID. Also, another argument can take place regards software based RAID versus dedicated RAID controller based RAID setup. Other storage experts might argue that RAID 5 should not be used and RAID 6 should be used instead. To be honest, what really matter is to know why and where use to use each RAID level. What matters is which RAID level is the most beneficial and most suitable for the requirements.
A lot of equipment is installed in server racks besides servers. These server devices serve different purposes such as cable management and energy supply. In this post, we will discover these devices and learn more about them and why are they used.
PDU
-Courtesy of gdftech
In short, PDU which stands for power distribution unit is an expensive power strip on steroid. So, it can be defined as a special type of power strips that distributes electricity to server and other devices. Moreover, they are designed to be efficient, safe and able to distribute sufficient energy to all server racks. PDUs excel when multiple three-phase power sources are used together to power server rack equipment.
UPS
Rack Mounted UPS (Courtesy of Eaton)
UPS which stands for Uninterrupted Power Supply is a device that either placed in a server rack or in a separate location and it is serves two purposes. First, it contains a battery pack that feeds server room equipment during a power outage for a finite time and prevents any data corruption due to power outage. Second, Uninterrupted Power Supplies cleans the electricity that feeds the devices. As a result, devices will work better and prevent power related faults. Modern smart UPSs are capable to notify system administrators about power outages and shut down devics safely when the batter is out to run out of charge.
KVM Switch
USB Based KVM Switch (Courtesy of D-Link)
KVM (Keyboard, video, Mouse) switch or known as KVM for short is a device that is used to allow a single mouse, keyboard and monitor screen to be used by multiple computers. Thus, less peripheral device in the server room, especially that most device are rarely accessed directly.
KVM can connect to devices in two different methods. First method is by using a USB and a video cables (VGA, HDMI or DVI) between each device and the KVM. The second method that is usually used by the higher end KVM switches is by depending on IP protocols to connect between the KVM and the devices i.e. using the current network infrastructure to connect remote machines to the KVM switch.
Patch Panel
Front and Read View of a Patch Panel
One of the main concepts in network cable management is decoupling. Decoupling means in this case is separating between access switches and end device, by adding a patch device in between. Adding a patch panel helps network and system administrators to reassign network cables between different network devices easily.
Patch panels consist of two sides. First, the rear side which is used to connect between the end machines and the patch panel. Second, the front side which is used to connect between patch panels are network devices.
Hemo’s Take
In real life, server racks have more equipment than mentioned here such as NAS, Tape drives and even GPS-based NTP servers. However, these devices the most important and about no proper server rack is without them.